I worked as a Research assistant under Dr. Davood Rafiei during Summer 2018 along side with Peter Elliot to build a tool to extract “facts” from articles. We employed the used of SpaCy as a library for Natural Language Processing in Python as well as neuralcoref for coreference resolution. Using spaCy, we built the dependancy trees of given sentences, and then based on some hand-coded rules, selected and formed facts in the form of triplets. Afterwards, the facts are categorized into non-mutual exclusive groups: Time-based, Past-tense, Transactions, Personnel, Communications and Organizational.
Example
Tervita's new CEO, John Cooper, is committed to providing employees with regular communication updates.
Our program produces the following relations.
Personnel relations: 2
ID:1 (John Cooper; [is] CEO [of]; Tervita)
ID:3 (John Cooper; [is]; Tervita's new CEO)
PastTense Contact relations: 1
ID:0 (Tervita's new CEO, John Cooper,; is committed; to providing employees with regular communication updates)
 This flowchart shows the overall process, where preprocessing was cleaning up the data and separating the data into separate sentences, as well as attempting coreference resolution with neuralcoref, since spaCy doesn’t deal with it.
This flowchart shows the overall process, where preprocessing was cleaning up the data and separating the data into separate sentences, as well as attempting coreference resolution with neuralcoref, since spaCy doesn’t deal with it.
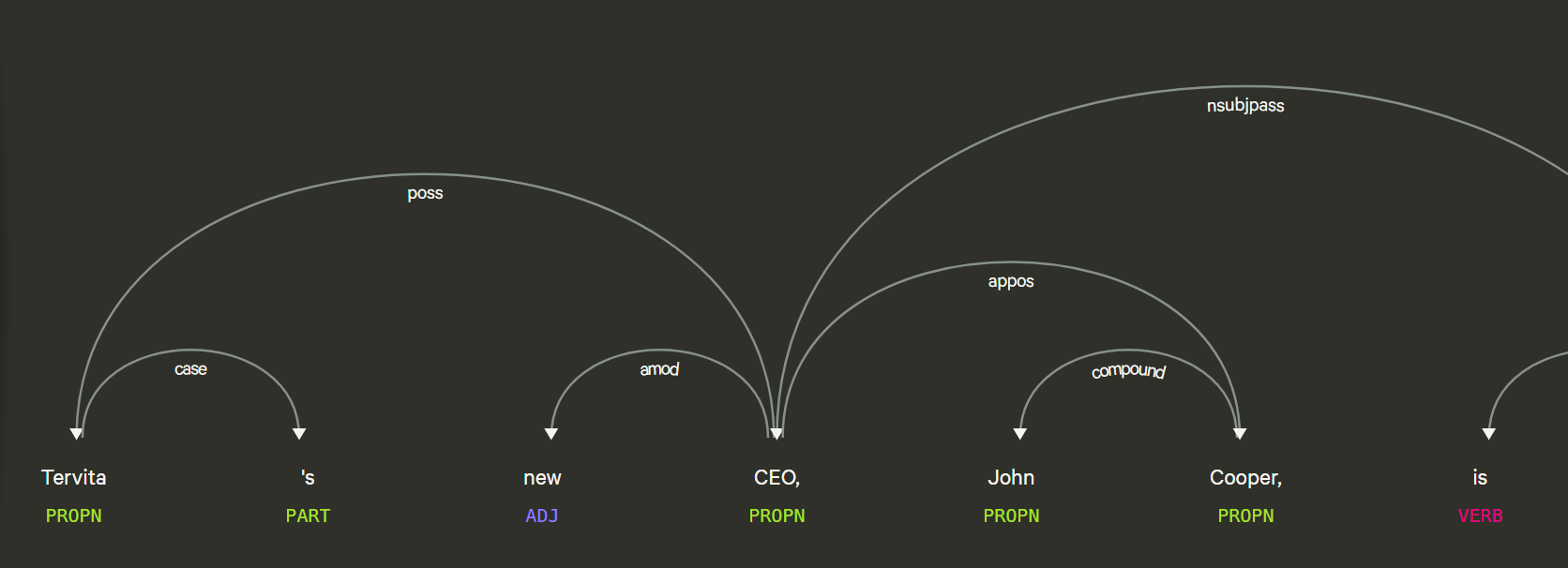 Here is an image of spaCy’s visualizer, showing the tree structure that can form from dependancies, which was what we used to identify certain patterns such as a Noun;Verb;Noun like pattern.
Here is an image of spaCy’s visualizer, showing the tree structure that can form from dependancies, which was what we used to identify certain patterns such as a Noun;Verb;Noun like pattern.